
The supply and demand of news during COVID-19 and assessment of questionable sources production – Nature.com

Searches data
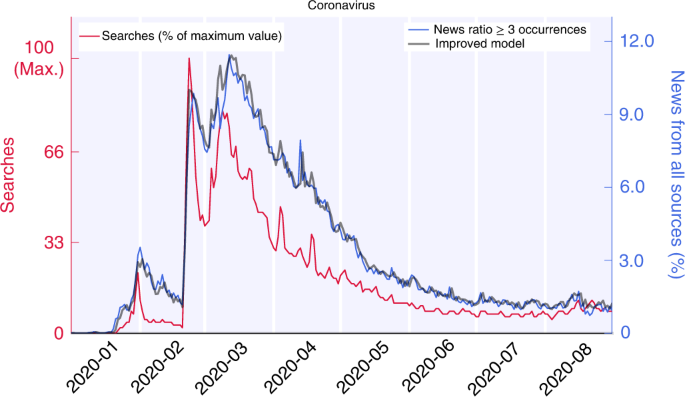
The information demand about a specific subject was obtained from Google Trends, a platform providing access to an anonymous sample of actual search requests made in the Google Search engine, from a selected location and time interval.
For each given keyword, Google Search returns a time series with values proportional to the number of times the keyword was searched each day. Since Google Search does not disclose the actual number of searches, the time-series values are rendered as percentages of the maximum number returned. As a result, data consist of integers within the interval 0–100. The time series of one keyword was referred to as the ‘Searches’ for that keyword and provided a measure of the interest it received.
The use of the ‘pytrends’ library for Python (https://github.com/GeneralMills/pytrends) enabled interaction with the Google Trends platform. The terms from Supplementary Fig. 1 were requested separately for the time ranging from 6 December 2019 to 31 August 2020 in Italy. These terms were ‘coronavirus’, ‘regionali’ (regional elections), ‘playstation’, ‘papa francesco’ (Pope Francesco), ‘eurovision’ (the European music contest) and ‘sondaggi’ (polls).
Google Trends also provided information about queries most searched with a specific keyword. In particular, the most popular queries related to the keyword ‘coronavirus’ (for example, ‘coronavirus’ news) were gathered. Such list is capped by Google Trends at a maximum of 25 related keywords, ordered by most searched to least, and denoted q1(t), …, q25(t), respectively, with t indicating the time and q0(t) being the time series of ‘coronavirus’ searches.
To compare the searches of a given keyword with its related keywords, it is necessary to put them on the same scale. To this end, searched items were queried in pairs. In this way, Google Trends normalized the two resulting time series to the highest of the maximums of the two. Given the two time series per request (qi−1(t), qi(t)), with i = 1, …, 25, a coefficient αi = maxt(qi−1(t))/maxt(qi(t)) was calculated. Thus, all the time series qi could be set on the same scale of q0, multiplying by (mathop{prod }nolimits_{j = 1}^{i}{alpha }_{j}). This procedure was needed so as not to lose resolution on keywords with a small number of queries. Having queried for pairs (q0(t), qi(t)) would have resulted in a rounding at 0 performed by Google Trends.
‘Coronavirus’-related queries were then aggregated by summing up their time series. Thus, ‘coronavirus oggi’ (coronavirus today), ‘coronavirus notizie’ (coronavirus news), ‘coronavirus ultime’ (coronavirus latest), ‘coronavirus ultime notizie’ (coronavirus latest news) and ‘coronavirus news’, were all aggregated into ‘coronavirus news’. Subsequently, we removed all queries that returned the same search results as another query. These were ‘coronavirus contagi’ (coronavirus infections) and ‘coronavirus in italia’ (coronavirus in Italy), which are duplicates of ‘contagi coronavirus’ (coronavirus infections) and ‘coronavirus italia’ (coronavirus Italy), respectively. Also, the query ‘corona’ was excluded because it has other meanings in Italian, namely ‘crown’, and it is also a famous brand of beer. Finally, the list of queries associated with ‘coronavirus’, ordered by the amount of searches, was: ‘news’, ‘italia’ (Italy), ‘lombardia’ (Lombardy), ‘sintomi’ (symptoms), ‘contagi’ (infections), ‘casi’ (cases), ‘morti’ (deaths), ‘bollettino’ (bulletin), ‘roma’ (Rome), ‘dati’ (data), ‘mondo’ (world), ‘mappa’ (map), ‘sicilia’ (Sicily), ‘veneto’, ‘campania’, ‘decreto’ (decree), ‘milano’ (Milan) and ‘piemonte’ (Piedmont).
News data
To analyse the news supply, we investigated the data provided by AGCOM, the Italian Authority for Communications Guarantees, which granted us access to the content of a vast number of Italian news sources published online and offline from 6 December 2019 to 31 August 2020 in Italy. These data included articles from printed and digital newspapers and information agencies, TV, radio sites and scientific sources.
Moreover, the data had a specific annotation on questionable sources. AGCOM compiled a list of these outlets by merging the lists from independent fact-checking organizations such as bufale.net, butac.it, facta.news and pagellapolitica.it.
The protocols of these organizations for checking individual news consist of addressing only verifiable facts or numbers, comparing versions from different sources and tracking the history of the contents (for example, reverse searching pictures to check for possible misuse). More details on their procedures can be found on their websites (https://pagellapolitica.it/progetto/index or https://www.bufale.net/come-lavoriamo/) and on the Code of Principles they subscribe to (https://ifcncodeofprinciples.poynter.org).
For the classification of the sources, specific taxonomies have been developed. A source can be classified as questionable for different reasons. The most common are: (1) being a ‘fake’ version of an actual newspaper, such as the source ‘Il Fatto Quotidaino’ faking ‘Il Fatto Quotidiano’ by switching the letters in its domain; (2) supporting well-known conspiracy theories, such as ‘Autismo Vaccini’ (translated as autism vaccines); and (3) click-baiting websites, with fabricated news and exaggerated titles. More details can be found on the organizations’ websites, where the lists of labelled sources are continuously updated (https://www.bufale.net/the-black-list-la-lista-nera-del-web/ or https://www.butac.it/the-black-list/).
The Authority verified the fact-checking organizations’ methodologies and legitimacy through the recognition of international organizations such as the International Fact-checkers Organizations, the Duke Reporters’ Lab or the European Digital Media Observatory. The Authority released the list of unreliable sources to its scientific partners only after it was used by independent scientific studies11,64,65,66,67. Also, the list provided by the Authority in 2020 was already adopted in one other study68.
All the sources annotated as questionable in our dataset are listed in Supplementary List 1. The source-based methodology is well-known and well-established in the current literature on disinformation8,69,70,71. We followed the same approach, which is particularly well-suited to studying the behaviour of unreliable suppliers, as in the present study. As a sanity check, albeit without being comprehensive, we manually inspected only a small randomly chosen sample of the almost 40,000 news items available.
However, the source-based approach implies some limitations. Sources annotated as questionable might not publish just questionable news, and news from the annotated sources might be misinformation of different degrees. In our approach, the sources annotated as questionable are assumed to be questionable to the same extent and static for the observed period. In principle, the percentage of questionable news items might vary from one source to another and over time. Future studies will address these limitations. For the present work, we assumed that the source annotations are reliable enough to represent the questionable supply, at least at the aggregated level we considered.
We pre-processed the data for duplicates and incomplete logs elimination. In particular, we excluded items from Facebook and Twitter sources since our purpose is to monitor the direct production of news and social media usually copy contents created elsewhere. Also, an outlier was found in the pieces of news coming from a source called ‘Non siamo soli’, which were reported for only a few days and therefore excluded. After the cleaning, the News from All Sources data consisted of 6,806,881 items from 554 different news sources, while the News from Questionable Sources data consisted of 134,793 items. Each data entry has a unique ID and contains, among other information, the title and the content of the piece of news, its date, its source and the annotation of belonging to the questionable sources list.
Needing to imitate the rationale underlying Google Trends data, where daily search counts refer to the query of specific keywords, we sought to find counts of daily keywords also in the news data. To do so, given a keyword (for example, ‘coronavirus’), we defined three different metrics: the piece of news containing the keyword at least once, those having the keyword at least three times, and finally, all the occurrences of a specific keyword. These three metrics were then normalized to the total number of news sources per day to level the press activity during weekends. For each model, we chose the metric with the best modelling performance. For the improved version of the VAR model described in equation (1) from the Results, the metric with at least three occurrences was selected, even if the other two showed similar performances. Instead, the most inclusive metric (at least one occurrence) was adopted when dealing with unreliable sources. This procedure was necessary to enhance the signal, given the low number of sources of News from Questionable Sources encountered. For consistency, News from All Sources was considered with the same metric (at least one occurrence) when comparing it with the News from Questionable Sources time series. The exact sample size (n) for each keyword is available in Table 3 as a discrete number for both sources of News from All Sources data and News from Questionable Sources data.
Following the same rationale, we adopted the first metric to filter for the keywords related to the ‘coronavirus’ subject described in the previous subsection. To do so, we selected the piece of news containing the keyword ‘coronavirus’ at least once and, in this subset, we counted the ones featuring the desired related keyword at least once. The values found were normalized to the total number of news pieces featuring the keyword ‘coronavirus’ at least once per day. We did this to get a proxy for the share of ‘coronavirus’ piece of information focused on the related keyword subdomain. We repeated this analysis for the subset of news mentioning the keyword ‘coronavirus’ at least once, coming from sources annotated as questionable. We then used the values extracted from this analysis to investigate the questionable supply in the ‘coronavirus’ context. The exact sample size (n) for each ‘coronavirus’-related keyword is available in Table 5 as a discrete number for both News from All Sources and News from Questionable Sources.
Time series analysis
Time series of Searches and News from All Sources (from Supplementary Fig. 1) were investigated with the VAR model62, using Python’s ‘statsmodels’ package for time-series analysis72. Data were regularized via x ↦ log(1 + x) transformation before fitting. For the VAR modelling, the number of lags d was determined as the parameter that minimized the Akaike information criterion63, with d ranging from 1–14. This modelling strategy was chosen to ensure the interpretability of the fitted model and its regression coefficients.
From the VAR model, we computed Granger-causality62 to test whether the queries’ values provided meaningful information to the prediction of news shares and vice versa. Since two tests were performed on the same data from a given subject (for the null hypotheses, ‘S does not Granger-cause NAS’ and ‘NAS does not Granger-cause S’), resulting P values were corrected by the Holm-Bonferroni method73. Thus, pairs of P values in Supplementary Fig. 2 were multiplied by 2 to control for family-wise error rate and to maintain comparability.
In Fig. 1 and Supplementary Fig. 3, the improved models for regression of the News from All Sources were derived by adjusting the VAR models to include Searches at time t. Lags were re-elaborated through the Akaike criterion as before, with similar results. These models were then compared against a null model that forecasts one day proportionally to the value of the day before to benchmark how beneficial the addition of regressing variables was to NAS prediction (Table 1).
To assess the semantic misalignment between News from All Sources and Searches from Supplementary Fig. 4 over the related queries associated to ‘coronavirus’ at a given time t, the cosine distance was calculated as d(S(t), N(t)) = 1 − S(t) ⋅ N(t)/∣S(t)∣ ∣N(t)∣, on the vectors S(t) = (S1(t), …, Sk(t)), N(t) = (N1(t), …, Nk(t)), where Si(t) and Ni(t) represented the searches and news, respectively, at time t for the i-th keyword associated to ‘coronavirus’, with ⋅ being the dot product and ∣ ⋅ ∣ being the Euclidean norm. Cosine distance was suitable for comparing high-dimensional vectors at different scales, and returned values in (0, 1) for vectors with non-negative entries such as S(t) and N(t).
Comparison of improved models’ coefficients
To assess the differences in the coefficients from the improved models of News from All Sources or News from Online Sources, and News from Questionable Sources, we performed a statistical hypothesis test on the basis of bootstrap. First, we created a bootstrap version of the daily values by sampling with replacement from the pool of news from those days that were unlabelled or labelled as questionable. Repeating this procedure many times for every day, we recreated 105 bootstrapped versions of the time series for News from All Sources (or News from Online Sources) and News from Questionable Sources. For each of them, we fitted the improved model and calculated Δ as the difference between the parameters of the model for the News from All Sources (or News from Online Sources) and the same parameters of the model for the News from Questionable Sources. As an example, we report in Supplementary Fig. 6 the distribution of the difference in the inertial term α1 of News from All Sources and News from Questionable Sources, that is, the bootstrap distribution. To challenge the null hypothesis Δ ≤ 0 against the alternative Δ > 0, we calculated the test’s P value as P = ∣Δ ≤ 0∣/(N + 1), where ∣Δ ≤ 0∣ is the number of bootstrap repeats where the hypothesis is true and N = 105 is the total number of repeats (note that 1 is added to the denominator to account for the Δ > 0 that is actually observed). The example above describes the left-tailed version of the testing procedure. Following the same rationale, the P value for the right-tailed test is P = ∣Δ ≥ 0∣/(N + 1). The results for this analysis are reported in Table 4.
Combined index validation
To define and validate the combined index from Fig. 3, we split the daily data from News from Questionable Sources concentration on ‘coronavirus’ into a training set (from 29 January 2020 to 20 March 2020) and a validation set (from 21 March 2020 onwards).
Thus, we defined the combined index as a linear combination of the two starting indices that best fitted the concentration of News from Questionable Sources, using a linear model with Gaussian noise on the training data. The ordinary least squares estimate (hat{sigma }) for the variance of the Gaussian noise was then calculated as the mean squared error (MSE) divided by the statistical degrees of freedom k (that is, the number of observations minus 2, which is the number of parameters in the model).
To assess the predictive potential of the combined index, we adopted the trained model to forecast the concentration of News from Questionable Sources in the validation set. The goodness of fit of this prediction was tested through the reduced chi-squared statistic, which is calculated as the MSE on the validation set divided by (hat{sigma }). This statistic is approximately distributed as a χ2 with as many degrees of freedom as the size of the validation set (that is, 51), leading to a P value of about 0.945. As such, the null hypothesis that the concentration of News from Questionable Sources for the keyword ‘coronavirus’ is distributed in agreement with the trained model cannot be rejected.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.


